星光麒麟端侧AI大模型应用“星语对话”首次亮相
|
近日,第八届瑞芯微开发者大会(RKDC2024)期间,基于大模型的星光麒麟端侧AI应用“星语对话”首次亮相。“星语对话”目前已完成技术路线验证并在RK3588上成功部署,可向端侧用户提供本地化生成式人工智能(AIGC)能力。 在软件技术分论坛上,麒麟软件专题分享了星光麒麟云边端的AI框架。目前,除了布局端侧AI大模型,星光麒麟AI框架还在不断提升云边端灵活协同的能力,提出了面向万物智联操作系统的云边端AI架构。
在端侧,“星语对话”已具备智能问答、逻辑生成和多语言等能力。在智能问答方面,能够模拟人与人之间的对话过程。当用户提出问题时,系统通过自然语言处理(NLP)理解问题,然后检索或推理相关信息,并将答案转化为自然语言回复用户。 在逻辑生成方面,通过数据清洗和数据预处理,基于模型训练自动调整权重和参数,最大程度地减少生成结果与真实文本之间的损失。在生成文本时,根据输入信息和已学习到的语言规律进行逻辑推理,识别和应用适当的逻辑规则,以更准确、合理且连贯地生成文本。 “星语对话”的多语言特性能够理解和处理多种语言,为用户提供跨语言的智能对话体验。通过训练不同语言的数据,在模型中实现语言间的知识传递,使得用户无论使用哪种语言都能得到高质量、智能化的回复。
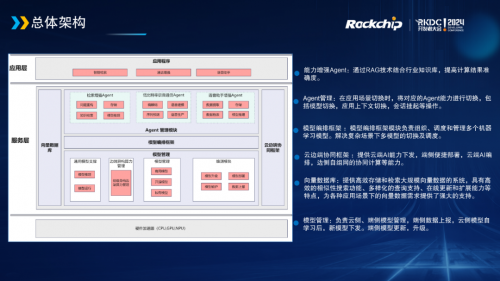
除端侧AI大模型的布局外,星光麒麟AI框架还在不断提升云边端灵活协同的能力,提出了面向万物智联操作系统的云边端AI架构。
例如通过RAG技术结合行业知识库,提高计算结果准确度;在应用场景切换时,将对应的Agent能力进行切换,包括模型切换,应用上下文切换,会话挂起等操作;模型编排框架模块负责组织、调度和管理多个机器学习模型,解决复杂场景下多模型的切换及调度;提供云端AI能力下发,端侧便捷部署,云端Al编排,边侧自组网的协同计算等能力;提供高效存储和检索大规模向量数据的系统,具有高效的相似性搜索功能、多样化的查询支持、在线更新和扩展能力等特点,为各种应用场景下的向量数据需求提供了强大的支持;负责云侧、端侧模型管理。端侧数据上报,云侧模型自学习后,新模型下发。端侧模型更新,升级。 不同场景的复杂度不同,对底层大模型的输出精准性要求有所侧重,云边端计算框架根据场景选择模型和算力来源,可灵活地在云端、边缘端或终端设备上执行特定的操作或计算任务。
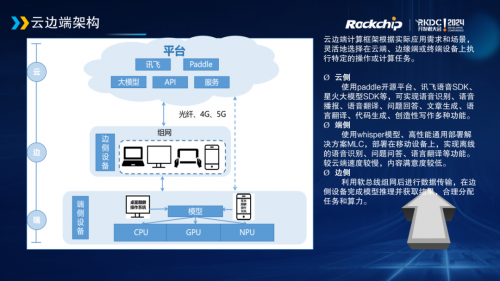
在云端部署方面,使用Paddle开源平台、讯飞语音SDK、星火大模型SDK等,实现语音识别、语音播报、语音翻译、问题回答、文章生成、语言翻译、代码生成、创造性写作等多种功能。 在边缘侧部署方面,利用软总线组网后进行数据传输,在边侧设备完成模型推理并获取结果,合理分配任务和算力。 在端侧部署方面,使用Whisper语音模型、高性能通用部署解决方案MLC,部署在移动设备上,实现离线的语音识别、问题问答、语言翻译等功能。 随着人工智能(AI)技术的不断发展,操作系统融入AI技术已成为一条必由之路。星光麒麟将利用AI技术不断提高操作系统的资源管理和调度能力,提升系统稳定性,为用户提供更加智能、高效和安全的服务体验,为人机物融合泛在计算提供支撑。 |